Table of Contents » Chapter 3 : Processing : Case Studies : Named Entity Recognition (NER)
Named Entity Recognition (NER)
Contents
- Overview
- The spaCy Library
- spaCy Examples
Entity extraction, also known as Named Entity Recognition (NER), is a set of techniques we can use in Python to locate and classify named entities mentioned in unstructured text (phrases, sentences, paragraphs, articles, documents, etc.) into pre-defined categories. These categories can include the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. Entity extraction is an important part of processing that helps in understanding text and extracting relevant information.
spaCy ↗ is one of the most popular Python libraries for natural language processing (NLP). It is designed for production use and offers fast performance for NLP tasks. It is well-suited for large-scale information extraction tasks. spaCy provides pre-trained models for multiple languages and supports tasks like tokenization, part-of-speech tagging, named entity recognition, dependency parsing, and text classification. It emphasizes efficiency and accuracy. spaCy's API is streamlined and intuitive, making it accessible for users who are new to NLP while still powerful for advanced users.
Google CoLab
If you are using Google CoLab, the spaCy library is already installed and available for use in any Notebook, so you can go straight to the code examples below.
IDEs like Visual Studio Code, PyCharm, or Others
If you are using an IDE like Visual Studio Code, PyCharm, or others, you'll need to install the spaCy library before you can use it. The common approach to install a library is to use the pip package manager in the terminal. Open a terminal and enter the following two commands:
# First use pip to install the library
pip install spacy
# Then install a language model. You can choose either the small model or large model, like this:
# Use the following if you want the small language model ...
python -m spacy download en_core_web_sm
# ... or the following if you want the large language model ...
python -m spacy download en_core_web_lgOfficial Documentation
For detailed documentation on spaCy, see the spaCy usage ↗ page.
Once you have spaCy and a language model installed, you can proceed using spaCy in your code. See the following section for some examples.
Code
import spacy
from spacy import displacy
import html
def perform_ner_and_visualize(file_path):
nlp = spacy.load("en_core_web_sm")
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
doc = nlp(text)
displacy_image = displacy.render(doc, style='ent', page=True, minify=True)
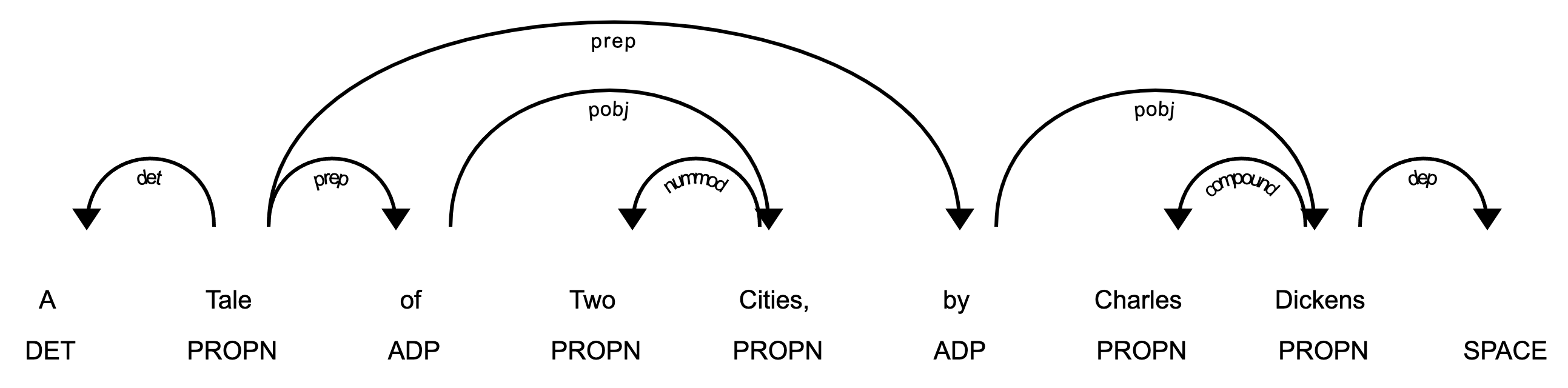
def visualize_sentence_dependencies(file_path):
nlp = spacy.load("en_core_web_sm")
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
doc = nlp(text)
first_sentence = next(doc.sents)
displacy.render(first_sentence, style='dep', jupyter=True, options={'distance': 100})
def visualize_all_sentence_dependencies(file_path):
nlp = spacy.load("en_core_web_sm")
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
doc = nlp(text)
for sentence in doc.sents:
displacy.render(sentence, style='dep', jupyter=True, options={'distance': 100})
print("\n" + "-"*80 + "\n")
if __name__ == "__main__":
file_path = "twocities.txt"
perform_ner_and_visualize(file_path)
# visualize_sentence_dependencies(file_path)
visualize_all_sentence_dependencies(file_path)Output