Table of Contents » Chapter 3 : Processing : Case Studies : Web Scraping
Web Scraping
Contents
Web scraping, also known as web harvesting or web data extraction, is the process of programmatically extracting data from websites. It involves making HTTP (protocol of the Internet) requests to a specific URL (web address), receiving the page's HTML content in response, and then parsing and extracting the needed information from it. Web scraping is a powerful tool for automating the collection of web-based data, which can be used for a wide range of applications, from data analysis and machine learning projects to competitive analysis and automated reporting.
Python is a popular choice for web scraping for several reasons, first, the freely available libraries available for Python used for web scraping. Also, Python can handle all aspects of the web scraping process, from making requests to parsing HTML and storing the extracted data.
The most following libraries are commonly used web scraping:
- Requests ↗ : The requests library is used to communicate via the HTTP protocol across the internet. With it, we can programmatically connect to online resources, such as web pages, and request data from those resources. See the full documentation for the requests library here ↗.
- Beautifulsoup ↗ : The beautifulsoup library is primarily used for parsing HTML and XML documents. It is great for extracting information from a webpage, allowing for easy navigation of the parse tree and searching for elements by their attributes. It is mainly used for web scraping. See the full documentation for the beautifulsoup library here ↗
The basic concepts of web scraping include the following:
- HTTP Requests: Web scraping relies on the ability to retrieve web pages programmatically (called an HTTP request). The requests provides the functionality to accomplish this task.
- HTML Parsing: Once a web page has been retrieved through a request, then it must be parsed to extract the information you need.
- Data Extraction: After parsing the HTML, the next step is to extract the specific pieces of data you're interested in. This often involves locating HTML elements by their class, id, or other attributes and retrieving their content.
- Data Storage: The final step in web scraping is storing the extracted data in a format suitable for your project, such as CSV, JSON, or a database.
Before diving into web scraping, it's crucial to understand the legal and ethical implications. Not all websites permit their data to be scraped, and ignoring a site's robots.txt file or terms of service may lead to legal consequences or your IP address being blocked. Always ensure that your web scraping activities are compliant with the website's policies and laws regarding data protection and privacy.
The first thing to be aware of when learning to scrape web pages is that when scraping with a library like beautifulsoup, it reads the source code behind what we see on the web page in a browser. The source code that defines how a webpage should appear is interpreted by the browser and is usually a combination of HTML, CSS, and possibly other languages, like JavaScript as well as others. This presents a challenge if you are not familar with these tools. The good news is that there are many examples online and in the Beautifulsoup documentation ↗. Let's take a look at a detailed example.
In this example, we will learn to scrape information from the Wikipedia - Pulitzer Prize for Fiction webpage.
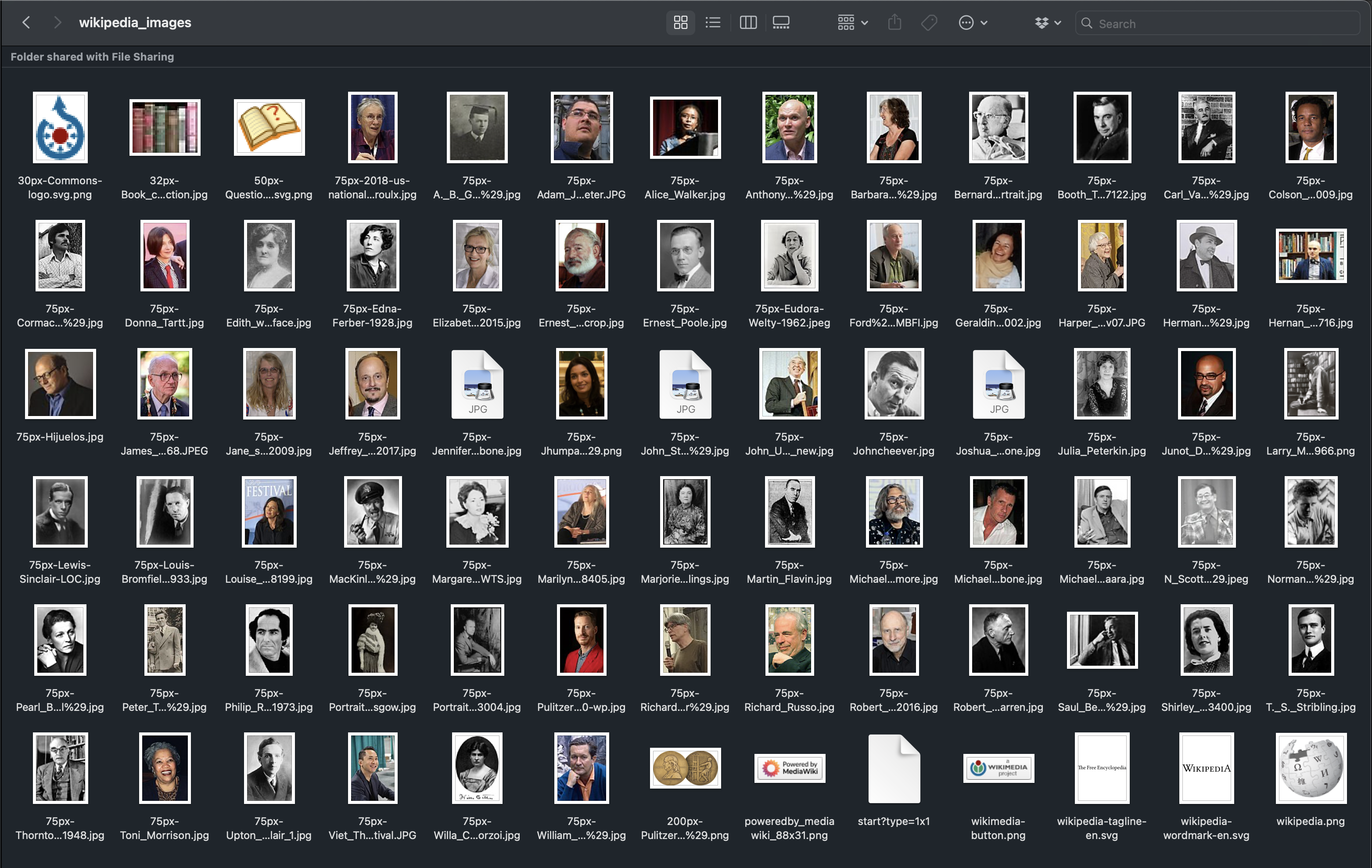
When we navigate to this webpage in a browser we see the visual version of the page as interpreted by the browser (left side of Figure 1.). Web scraping though uses the source code (right side of Figure 1.), which we can see for any webpage by taking the following steps:
- Position your mouse cursor in any blank space on the page (not over an image, link or text)
- If you're using a Windows computer, right-click. If you're using a Mac, press Shift and then right-click.
- On the pop-up menu, click View page source.
- A new tab will open to display the source code for that webpage, as seen in Figure 1.
In this first code example, we will scrape the page to get the title of the page. This process will involve sending a request to the site using the requests library, using the beautifulsoup library to parse the page contents (HTML), and the extracting and storing the data (the page title) we collect from the page.
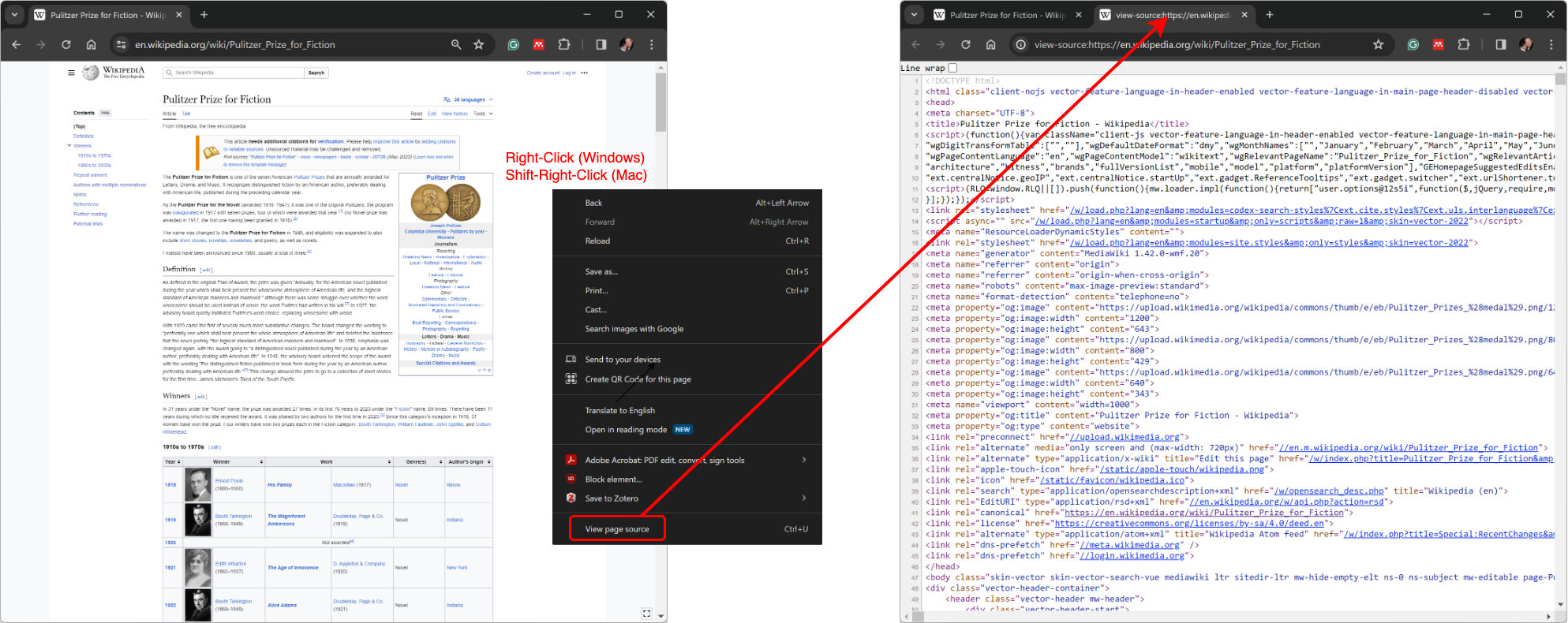
Before we start coding, if we look in the source code of the page, we'll see a line like this:
<title>Pulitzer Price for Fiction - Wikipedia</title>That line of HTML is interpreted by the browser as the title of the webpage, which is display in the browser tab (top of the browser), as shown in Figure 2 below.
This will be our first code example, to programmatically get the webpage title using the requests and beautifulsoup libraries.
Code
import requests
from bs4 import BeautifulSoup
url = 'https://en.wikipedia.org/wiki/Pulitzer_Prize_for_Fiction'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
page_title = soup.title.text.strip()
print(f"Page Title: {page_title}")
else:
print("Failed to retrieve the webpage")Output
Page Title: Pulitzer Prize for Fiction - WikipediaCode Details
- Code Lines 1 and 2: First we import the libraries requests and beautifulsoup.
- Code Line 4: Next, we'll declare a variable to hold the URL and initialize it to the web address of the page of interest.
- Code Line 5: We then use the get() method of the requests object to connect to the url, which returns a response from the website.
- Code Line 6: We use an decision statement to check the status of the returned response, if it is a status code of 200 that means we have a valid response.
- Code Line 7: When we have a valid response, then we can use beautifulsoup to parse the text of the response and store it in a variable (soup), which will provide us with the source code of the webpage.
- Code Line 8: With the webpage source code, we can use the soup variable's attribute .title to get the webpage title out of the source code.
- Code Line 9: We print the title of the webpage that we scraped from the source code of the page.
- Code Lines 10 and 11: If the status code of the response is not 200, then we'll print an error message.
A common web scraping task is to scrape all links (<a> HTML tags) that exist on a webpage. In this next example we'll scrape all of the links from the Wikipedia - Pulitzer Prize for Fiction webpage.
Code
import requests
from bs4 import BeautifulSoup
url = 'https://en.wikipedia.org/wiki/Pulitzer_Prize_for_Fiction'
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
for link in soup.find_all('a'):
href = link.get('href')
if href and href.startswith('http'):
print(href)
else:
print("Failed to retrieve the webpage")Output
https://donate.wikimedia.org/wiki/Special:FundraiserRedirector?utm_source=donate&utm_medium=sidebar&utm_campaign=C13_en.wikipedia.org&uselang=en
https://af.wikipedia.org/wiki/Pulitzerprys_vir_Fiksie
https://ar.wikipedia.org/wiki/%D8%AC%D8%A7%D8%A6%D8%B2%D8%A9_%D8%A8%D9%88%D9%84%D9%8A%D8%AA%D8%B2%D8%B1_%D8%B9%D9%86_%D9%81%D8%A6%D8%A9_%D8%A7%D9%84%D8%A3%D8%B9%D9%85%D8%A7%D9%84_%D8%A7%D9%84%D8%AE%D9%8A%D8%A7%D9%84%D9%8A%D8%A9
https://bn.wikipedia.org/wiki/%E0%A6%95%E0%A6%A5%E0%A6%BE%E0%A6%B8%E0%A6%BE%E0%A6%B9%E0%A6%BF%E0%A6%A4%E0%A7%8D%E0%A6%AF%E0%A7%87_%E0%A6%AA%E0%A7%81%E0%A6%B2%E0%A6%BF%E0%A7%8E%E0%A6%9C%E0%A6%BE%E0%A6%B0_%E0%A6%AA%E0%A7%81%E0%A6%B0%E0%A6%B8%E0%A7%8D%E0%A6%95%E0%A6%BE%E0%A6%B0
https://be.wikipedia.org/wiki/%D0%9F%D1%83%D0%BB%D1%96%D1%82%D1%86%D1%8D%D1%80%D0%B0%D1%9E%D1%81%D0%BA%D0%B0%D1%8F_%D0%BF%D1%80%D1%8D%D0%BC%D1%96%D1%8F_%D0%B7%D0%B0_%D0%BC%D0%B0%D1%81%D1%82%D0%B0%D1%86%D0%BA%D1%83%D1%8E_%D0%BA%D0%BD%D1%96%D0%B3%D1%83
https://bs.wikipedia.org/wiki/Pulitzerova_nagrada_za_knji%C5%BEevno_djelo
https://ca.wikipedia.org/wiki/Premi_Pulitzer_d%27Obres_de_Ficci%C3%B3
https://de.wikipedia.org/wiki/Pulitzer-Preis/Belletristik
https://el.wikipedia.org/wiki/%CE%92%CF%81%CE%B1%CE%B2%CE%B5%CE%AF%CE%BF_%CE%A0%CE%BF%CF%8D%CE%BB%CE%B9%CF%84%CE%B6%CE%B5%CF%81_(%CE%9C%CF%85%CE%B8%CE%BF%CF%80%CE%BB%CE%B1%CF%83%CE%AF%CE%B1%CF%82)
https://es.wikipedia.org/wiki/Premio_Pulitzer_de_Ficci%C3%B3n
https://eu.wikipedia.org/wiki/Pulitzer_Saria_Fikzioan
https://fa.wikipedia.org/wiki/%D8%AC%D8%A7%DB%8C%D8%B2%D9%87_%D9%BE%D9%88%D9%84%DB%8C%D8%AA%D8%B2%D8%B1_%D8%A8%D8%B1%D8%A7%DB%8C_%D8%AF%D8%A7%D8%B3%D8%AA%D8%A7%D9%86
https://fr.wikipedia.org/wiki/Prix_Pulitzer_de_la_fiction
https://fy.wikipedia.org/wiki/Pulitzerpriis_foar_Fiksje
https://ko.wikipedia.org/wiki/%ED%93%B0%EB%A6%AC%EC%B2%98%EC%83%81_%ED%94%BD%EC%85%98_%EB%B6%80%EB%AC%B8
https://hr.wikipedia.org/wiki/Pulitzerova_nagrada_za_knji%C5%BEevno_djelo
https://it.wikipedia.org/wiki/Premio_Pulitzer_per_la_narrativa
https://ka.wikipedia.org/wiki/%E1%83%9E%E1%83%A3%E1%83%9A%E1%83%98%E1%83%AA%E1%83%94%E1%83%A0%E1%83%98%E1%83%A1_%E1%83%9E%E1%83%A0%E1%83%94%E1%83%9B%E1%83%98%E1%83%90_%E1%83%9B%E1%83%AE%E1%83%90%E1%83%A2%E1%83%95%E1%83%A0%E1%83%A3%E1%83%9A_%E1%83%9A%E1%83%98%E1%83%A2%E1%83%94%E1%83%A0%E1%83%90%E1%83%A2%E1%83%A3%E1%83%A0%E1%83%90%E1%83%A8%E1%83%98
https://sw.wikipedia.org/wiki/Tuzo_ya_Pulitzer_ya_Bunilizi
https://la.wikipedia.org/wiki/Praemium_Pulitzer_mythistoriis_dicatum
https://hu.wikipedia.org/wiki/Pulitzer-d%C3%ADjas_reg%C3%A9nyek_list%C3%A1ja
https://nl.wikipedia.org/wiki/Pulitzerprijs_voor_fictie
https://ja.wikipedia.org/wiki/%E3%83%94%E3%83%A5%E3%83%BC%E3%83%AA%E3%83%83%E3%83%84%E3%82%A1%E3%83%BC%E8%B3%9E_%E3%83%95%E3%82%A3%E3%82%AF%E3%82%B7%E3%83%A7%E3%83%B3%E9%83%A8%E9%96%80
https://no.wikipedia.org/wiki/Pulitzerprisen_for_skj%C3%B8nnlitteratur
https://uz.wikipedia.org/wiki/Fantastik_adabiyot_bo%CA%BByicha_Pulitser_mukofoti
https://pa.wikipedia.org/wiki/%E0%A8%97%E0%A8%B2%E0%A8%AA_%E0%A8%B2%E0%A8%88_%E0%A8%AA%E0%A9%81%E0%A8%B2%E0%A8%BF%E0%A8%A4%E0%A8%9C%E0%A8%BC%E0%A8%B0_%E0%A8%AA%E0%A9%81%E0%A8%B0%E0%A8%B8%E0%A8%95%E0%A8%BE%E0%A8%B0
https://pnb.wikipedia.org/wiki/%D9%81%DA%A9%D8%B4%D9%86_%D9%84%D8%A6%DB%8C_%D9%BE%D9%84%D8%AA%D8%B2%D8%B1_%D8%A7%D9%86%D8%B9%D8%A7%D9%85
https://pl.wikipedia.org/wiki/Nagroda_Pulitzera_w_dziedzinie_beletrystyki
https://pt.wikipedia.org/wiki/Pr%C3%A9mio_Pulitzer_de_Fic%C3%A7%C3%A3o
https://ro.wikipedia.org/wiki/Premiul_Pulitzer_pentru_fic%C8%9Biune
https://ru.wikipedia.org/wiki/%D0%9F%D1%83%D0%BB%D0%B8%D1%82%D1%86%D0%B5%D1%80%D0%BE%D0%B2%D1%81%D0%BA%D0%B0%D1%8F_%D0%BF%D1%80%D0%B5%D0%BC%D0%B8%D1%8F_%D0%B7%D0%B0_%D1%85%D1%83%D0%B4%D0%BE%D0%B6%D0%B5%D1%81%D1%82%D0%B2%D0%B5%D0%BD%D0%BD%D1%83%D1%8E_%D0%BA%D0%BD%D0%B8%D0%B3%D1%83
https://sq.wikipedia.org/wiki/%C3%87mimi_Pulitzer_p%C3%ABr_vep%C3%ABr_letrare
https://simple.wikipedia.org/wiki/Pulitzer_Prize_for_Fiction
https://sh.wikipedia.org/wiki/Pulitzerova_nagrada_za_fikciju
https://fi.wikipedia.org/wiki/Pulitzerin_kaunokirjallisuuspalkinto
https://sv.wikipedia.org/wiki/Pulitzerpriset_f%C3%B6r_sk%C3%B6nlitteratur
https://tr.wikipedia.org/wiki/Kurgu_dal%C4%B1nda_Pulitzer_%C3%96d%C3%BCl%C3%BC
https://uk.wikipedia.org/wiki/%D0%9F%D1%83%D0%BB%D1%96%D1%82%D1%86%D0%B5%D1%80%D1%96%D0%B2%D1%81%D1%8C%D0%BA%D0%B0_%D0%BF%D1%80%D0%B5%D0%BC%D1%96%D1%8F_%D0%B7%D0%B0_%D1%85%D1%83%D0%B4%D0%BE%D0%B6%D0%BD%D1%8E_%D0%BA%D0%BD%D0%B8%D0%B3%D1%83
https://vi.wikipedia.org/wiki/Gi%E1%BA%A3i_Pulitzer_cho_t%C3%A1c_ph%E1%BA%A9m_h%C6%B0_c%E1%BA%A5u
https://zh.wikipedia.org/wiki/%E6%99%AE%E7%AB%8B%E8%8C%B2%E5%B0%8F%E8%AA%AA%E7%8D%8E
https://www.wikidata.org/wiki/Special:EntityPage/Q833633#sitelinks-wikipedia
https://www.wikidata.org/wiki/Special:EntityPage/Q833633
https://www.google.com/search?as_eq=wikipedia&q=%22Pulitzer+Prize+for+Fiction%22
https://www.google.com/search?tbm=nws&q=%22Pulitzer+Prize+for+Fiction%22+-wikipedia&tbs=ar:1
https://www.google.com/search?&q=%22Pulitzer+Prize+for+Fiction%22&tbs=bkt:s&tbm=bks
https://www.google.com/search?tbs=bks:1&q=%22Pulitzer+Prize+for+Fiction%22+-wikipedia
https://scholar.google.com/scholar?q=%22Pulitzer+Prize+for+Fiction%22
https://www.jstor.org/action/doBasicSearch?Query=%22Pulitzer+Prize+for+Fiction%22&acc=on&wc=on
http://www.pulitzer.org/prize-winners-by-year/1917
http://www.pulitzer.org/prize-winners-by-category/261
https://books.google.com/books?id=Yjj7FiO4p44C
https://archive.org/details/pulitzerprizeshi00hohe
https://archive.org/details/pulitzerprizeshi00hohe/page/55
https://www.nytimes.com/1984/05/11/books/publishing-pulitzer-controversies.html
https://www.worldcat.org/issn/0362-4331
https://www.nytimes.com/1984/05/11/books/publishing-pulitzer-controversies.html
https://www.worldcat.org/oclc/811400780
http://www.pulitzer.org/prize-winners-by-year/2009
http://www.pulitzer.org/prize-winners-by-year/2010
http://www.pulitzer.org/prize-winners-by-year/2011
http://www.pulitzer.org/prize-winners-by-year/2012
http://www.pulitzer.org/prize-winners-by-year/2013
http://www.pulitzer.org/prize-winners-by-year/2014
http://www.pulitzer.org/prize-winners-by-year/2015
http://www.pulitzer.org/prize-winners-by-year/2016
http://www.pulitzer.org/prize-winners-by-year/2017
http://www.pulitzer.org/prize-winners-by-year/2018
http://www.pulitzer.org/prize-winners-by-year/2019
http://www.pulitzer.org/prize-winners-by-year/2020
https://www.pulitzer.org/prize-winners-by-year/2021
https://www.pulitzer.org/prize-winners-by-year
https://www.publishersweekly.com/pw/by-topic/industry-news/awards-and-prizes/article/92233-demon-copperhead-trust-his-name-is-george-floyd-among-2023-pulitzer-prize-winners.html
https://www.pulitzer.org/prize-winners-by-year
https://www.pulitzer.org/prize-winners-by-year
https://commons.wikimedia.org/wiki/Category:Pulitzer_Prize_for_Fiction_winners
https://commons.wikimedia.org/wiki/Category:Pulitzer_Prize_for_the_Novel_winners
http://www.pulitzer.org/
http://www.pulitzer.org/prize-winners-by-category/261
http://www.pulitzer.org/prize-winners-by-category/219
https://standardebooks.org/collections/pulitzer-prize-winners
https://pulitzerprizefiction.wordpress.com/
http://www.newyorker.com/books/page-turner/letter-from-the-pulitzer-fiction-jury-what-really-happened-this-year
http://www.newyorker.com/books/page-turner/letter-from-the-pulitzer-fiction-jury-part-ii-how-to-define-greatness
https://en.wikipedia.org/w/index.php?title=Pulitzer_Prize_for_Fiction&oldid=1209376284
https://foundation.wikimedia.org/wiki/Special:MyLanguage/Policy:Privacy_policy
https://foundation.wikimedia.org/wiki/Special:MyLanguage/Policy:Universal_Code_of_Conduct
https://developer.wikimedia.org
https://stats.wikimedia.org/#/en.wikipedia.org
https://foundation.wikimedia.org/wiki/Special:MyLanguage/Policy:Cookie_statement
https://wikimediafoundation.org/
https://www.mediawiki.org/Code Details
- Code Lines 1 and 2: First we import the libraries requests and beautifulsoup.
- Code Line 4: Next, we'll declare a variable to hold the URL and initialize it to the web address of the page of interest.
- Code Line 5: We then use the get() method of the requests object to connect to the url, which returns a response from the website.
- Code Line 6: We use an decision statement to check the status of the returned response, if it is a status code of 200 that means we have a valid response.
- Code Line 7: When we have a valid response, then we can use beautifulsoup to parse the text of the response and store it in a variable (soup), which will provide us with the source code of the webpage.
- Code Line 8: Next we we will use the soup variable's method .find_all() to get the all of the webpage <a> HTML tags that exist in the source code, and we will loop through each one found.
- Code Line 9: For each <a> tag found, we use the get() method of the link to get the URL of the link.
- Code Line 10 and 11: If the link begins with 'http', which indicates a full URL address, then we print it.
- Code Lines 12 and 13: If the status code of the response is not 200, then we'll print an error message.
In this next example we will scrape the Wikipedia - Pulitzer Prize for Fiction webpage to get the list of prize winners.
Code
import requests
from bs4 import BeautifulSoup
url = 'https://en.wikipedia.org/wiki/Pulitzer_Prize_for_Fiction'
response = requests.get(url)
prizes = []
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
tables = soup.find_all('table', class_='wikitable')
for table in tables:
rows = table.find_all('tr')
for row in rows[1:]:
cells = row.find_all('td')
if len(cells) >= 2:
year = cells[0].text.strip()
if cells[1].find('a'):
title = cells[1].find('a').text.strip()
else:
title = cells[1].text.strip()
author = cells[2].text.strip() if len(cells) >= 3 else "N/A"
prizes.append([year, title, author])
for prize in prizes:
print(f"{prize[0]}, {prize[1]}, {prize[2]}")
else:
print("Failed to retrieve the webpage")Output
1918, Ernest Poole, His Family
1919, Booth Tarkington, The Magnificent Ambersons
1920, [a], N/A
1921, Edith Wharton, The Age of Innocence
1922, Booth Tarkington, Alice Adams
1923, Willa Cather, One of Ours
1924, Margaret Wilson, The Able McLaughlins
1925, Edna Ferber, So Big
1926, Sinclair Lewis, Arrowsmith[b]
1927, Louis Bromfield, Early Autumn
1928, Thornton Wilder, The Bridge of San Luis Rey
1929, Julia Peterkin, Scarlet Sister Mary
1930, Oliver La Farge, Laughing Boy
1931, Margaret Ayer Barnes, Years of Grace
1932, Pearl S. Buck, The Good Earth
1933, T. S. Stribling, The Store
1934, Caroline Miller, Lamb in His Bosom
1935, Josephine Winslow Johnson, Now in November
1936, Harold L. Davis, Honey in the Horn
1937, Margaret Mitchell, Gone with the Wind
1938, John Phillips Marquand, The Late George Apley
1939, Marjorie Kinnan Rawlings, The Yearling
1940, John Steinbeck, The Grapes of Wrath
1941, [c], N/A
1942, Ellen Glasgow, In This Our Life
1943, Upton Sinclair, Dragon's Teeth
1944, Martin Flavin, Journey in the Dark
1945, John Hersey, A Bell for Adano
1946, [d], N/A
1947, Robert Penn Warren, All the King's Men
1948, James A. Michener, Tales of the South Pacific
1949, James Gould Cozzens, Guard of Honor
1950, A. B. Guthrie, The Way West
1951, Conrad Richter, The Town
1952, Herman Wouk, The Caine Mutiny
1953, Ernest Hemingway, The Old Man and the Sea
1954, [e], N/A
1955, William Faulkner, A Fable
1956, MacKinlay Kantor, Andersonville
1957, [f], N/A
1958, James Agee, A Death in the Family (posthumously)
1959, Robert Lewis Taylor, The Travels of Jaimie McPheeters
1960, Allen Drury, Advise and Consent
1961, Harper Lee, To Kill a Mockingbird
1962, Edwin O'Connor, The Edge of Sadness
1963, William Faulkner, The Reivers (posthumously)
1964, [g], N/A
1965, Shirley Ann Grau, The Keepers of the House
1966, Katherine Anne Porter, Collected Stories
1967, Bernard Malamud, The Fixer
1968, William Styron, The Confessions of Nat Turner
1969, N. Scott Momaday, House Made of Dawn
1970, Jean Stafford, Collected Stories
1971, [h], N/A
1972, Wallace Stegner, Angle of Repose
1973, Eudora Welty, The Optimist's Daughter
1974, [i], N/A
1975, Michael Shaara, The Killer Angels
1976, Saul Bellow, Humboldt's Gift
1977, [j], N/A
1978, James Alan McPherson, Elbow Room
1979, John Cheever, The Stories of John Cheever
1980, Norman Mailer, The Executioner's Song
1981, John Kennedy Toole, A Confederacy of Dunces (posthumously)
1982, John Updike, Rabbit Is Rich
1983, Alice Walker, The Color Purple
1984, William Kennedy, Ironweed
1985, Alison Lurie, Foreign Affairs
1986, Larry McMurtry, Lonesome Dove
1987, Peter Taylor, A Summons to Memphis
1988, Toni Morrison, Beloved
1989, Anne Tyler, Breathing Lessons
1990, Oscar Hijuelos, The Mambo Kings Play Songs of Love
1991, John Updike, Rabbit At Rest
1992, Jane Smiley, A Thousand Acres
1993, Robert Olen Butler, A Good Scent from a Strange Mountain
1994, E. Annie Proulx, The Shipping News
1995, Carol Shields, The Stone Diaries
1996, Richard Ford, Independence Day
1997, Steven Millhauser, Martin Dressler: The Tale of an American Dreamer
1998, Philip Roth, American Pastoral
1999, Michael Cunningham, The Hours
2000, Jhumpa Lahiri, Interpreter of Maladies
2001, Michael Chabon, The Amazing Adventures of Kavalier & Clay
2002, Richard Russo, Empire Falls
2003, Jeffrey Eugenides, Middlesex
2004, Edward P. Jones, The Known World
2005, Marilynne Robinson, Gilead
2006, Geraldine Brooks, March
2007, Cormac McCarthy, The Road
2008, Junot Díaz, The Brief Wondrous Life of Oscar Wao
2009, Elizabeth Strout, Olive Kitteridge[k]
2010, Paul Harding, Tinkers[l]
2011, Jennifer Egan, A Visit from the Goon Squad[m]
2012, [11], Karen Russell, Swamplandia!David Foster Wallace, The Pale King (posthumously)Denis Johnson, Train Dreams
2013, Adam Johnson, The Orphan Master's Son[n]
2014, Donna Tartt, The Goldfinch[o]
2015, Anthony Doerr, All the Light We Cannot See[p]
2016, Viet Thanh Nguyen, The Sympathizer[q]
2017, Colson Whitehead, The Underground Railroad[r]
2018, Andrew Sean Greer, Less[s]
2019, Richard Powers, The Overstory[t]
2020, Colson Whitehead, The Nickel Boys[u]
2021, Louise Erdrich, The Night Watchman[v]
2022, Joshua Cohen, The Netanyahus: An Account of a Minor and Ultimately Even Negligible Episode in the History of a Very Famous Family[w]
2023[22], Hernan Diaz, Trust[x]
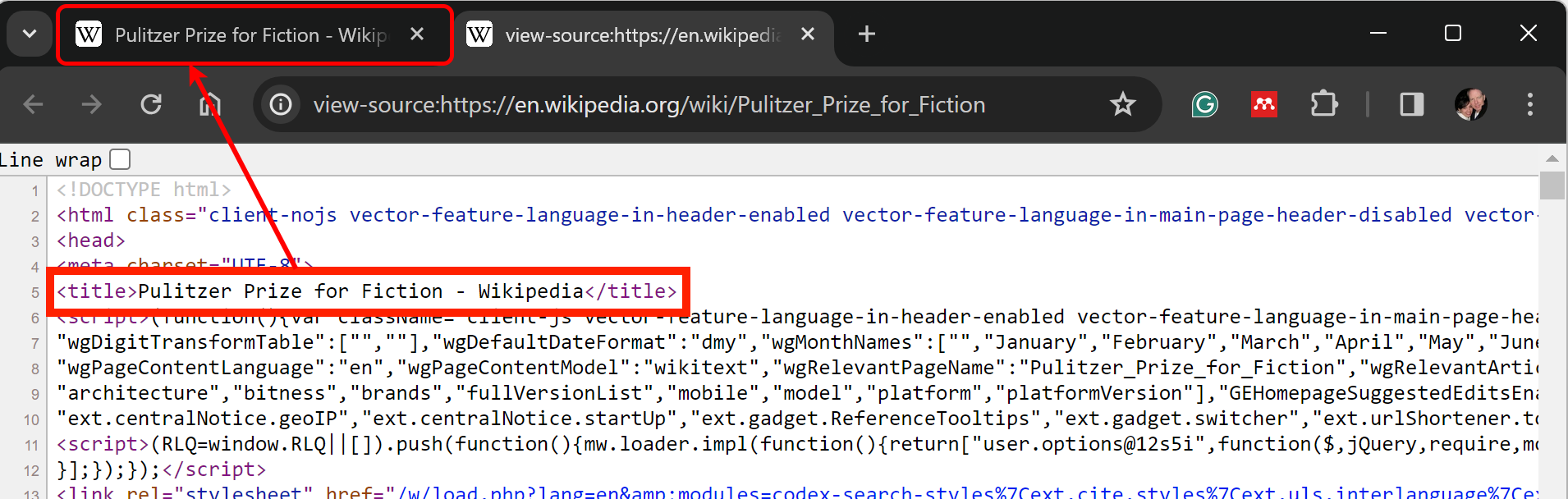
Barbara Kingsolver (b. 1955), Demon Copperhead, Harper (2022)In this next example we will scrape the Wikipedia - Pulitzer Prize for Fiction webpage and download all images on the page. This example is a bit more complex, but provides a good example of a more involved coding example.
Code
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def download_images(url, folder_path):
if not os.path.exists(folder_path):
os.makedirs(folder_path)
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, "html.parser")
images = soup.find_all("img")
for img in images:
src = img.get("src")
src = urljoin(url, src)
filename = os.path.join(folder_path, src.split("/")[-1])
with requests.get(src, stream=True) as r:
with open(filename, "wb") as f:
for chunk in r.iter_content(chunk_size=8192):
f.write(chunk)
print(f"Downloaded {filename}")
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
# Main
url = 'https://en.wikipedia.org/wiki/Pulitzer_Prize_for_Fiction'
folder_path = './downloaded_images'
download_images(url, folder_path)Output
The output of this code example is the set of images downloaded from the Pulitzer webpage to my local computer as seen in Figure 3.