



Table of Contents » Chapter 3 : Processing : Repetition : Parsing Data
Parsing Data
Contents
Overview
In Chapter 2, I introduced numerous concepts about data and ways in which we might acquire data to process in our programs. String data in the forms of characters, words, phrases, sentences, paragraphs, etc. are very common in computing and often need to be processed in many different ways. Examples of processing data include counting characters or words, locating instances of particular words or phrases, extracting key words, names, places, dates (often called entitied), validating important information in textual data, and many others. On this page we will explore parsing strings of several types.
While we know how to read the entire contents of a file into a variable and print it, we often need to analyze the contents of a file more closely than its entire contents. In order to examine long strings more closely, we use a technique called parsing.
Concept: Parsing
Parsing strings in Python involves analyzing a string's structure and extracting specific data from it according to a predefined pattern or structure. This process is essential in various applications, such as data analysis, web scraping, and configuration file management. Python offers multiple methods and libraries to facilitate string parsing, including built-in functions like split() for dividing a string into a list of substrings (called tokens) based on a delimiter, and strip() for trimming whitespace. For more complex parsing needs, Python provides the re module, which supports regular expressions allowing for sophisticated searching, matching, and manipulation of string patterns. This capability enables developers to extract specific pieces of information from strings, validate string formats, or transform strings in powerful ways, adapting to the diverse needs of different programming scenarios.
Here is a visual representation of parsing a string for the purposes of counting the number of words in the string:
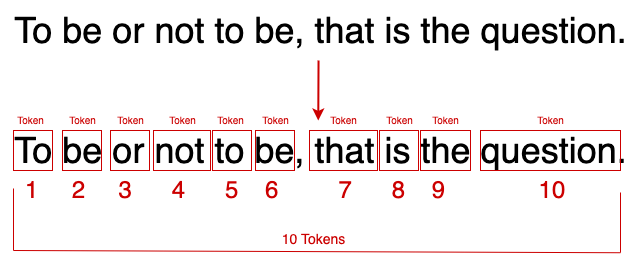
Concept: Token
Tokens in the context of string data refer to the individual components or pieces that result from dividing a string based on specific criteria, such as delimiters. Tokenization is the process of splitting a string into these smaller parts or tokens, which can be words, numbers, or symbols, depending on the content of the string and the rules applied for splitting. This concept is fundamental in text processing, parsing, and natural language processing (NLP) tasks, where analyzing and understanding the textual data at a granular level is essential. For example, when processing a sentence, tokenization might involve splitting the sentence into individual words or punctuation marks. Python's split() method on strings is a straightforward way to tokenize a string based on whitespace or other specified delimiters. Additionally, libraries like NLTK (Natural Language Toolkit) provide more sophisticated tools for tokenization, capable of handling complex patterns, such as separating contractions or distinguishing punctuation. Tokenization is a crucial first step in preparing text for further analysis, such as counting word frequencies, performing sentiment analysis, or building machine learning models for text classification.
Here is a visual representation of parsing a string for the purposes of counting the number of words in the string:
One of the first decisions we need to make when parsing string data is what to do about punctuation. In some cases, we'll want to preserve punctuation during parsing, but mostly commonly we'll remove punctuation so that our parsed tokens are independent of punctuation that existed in the original string. There are a number of approaches we can use to remove punctuation from a string. For now, we'll use repetition to do this, and then later we'll learn more efficient approaches.
Let's use the To be or not to be, that is the question. string example above for an example. In this string, there are two punctuation characters, the comma and the ending period. We could simply use the string replace() method to remove the two punctuation characters, like this:
s = "To be or not to be, that is the question."
print(s)
s = s.replace(",","")
print(s)
s = s.replace(".","")
print(s)Output
To be or not to be, that is the question.
To be or not to be that is the question.
To be or not to be that is the question
While this works, it's really restricted to the one string example we have right now. What about other strings with different punctuation in them?
A bit more of a generic example would be to use a list of punctation characters we want to eliminate from any string through the use of comparison and repetition (loop) to remove any of the punctuation characters we don't want in our strings. Here's an example:
shake_string = "To be or not to be, that is the question."
out_string = ""
punctuation = ["!", "\"", "#", "$", "%", "&", "\'",
"(", ")", "*", "+", ",", "-", ".",
"/", ":", ";", "<", "=", ">", "?",
"@", "[", "\\", "]", "^", "_", "{",
"|", "}", "~", "`", "."]
for s in shake_string:
if s not in punctuation:
out_string += s
print(shake_string)
print(out_string)Output
To be or not to be, that is the question.
To be or not to be that is the questionCode Details
- Note:
- This code example combines several key concepts we have learned thus far: variables, strings, lists, for loops, decisions, indentation, nested indentation, and assignment operator cominations (+= in this example).
- Code Line 1: First we assign our string to a variable.
- Code Line 2: We'll also create another variable that we will use to create a new string without the punctuation.
- Code Lines 3 thru 7: Next, we'll create a reusable list containing all of the punctuation characters we want to remove from any string we process in this code, that is, any string we assign to our string_to_process variable.
- Notes:
- There are special cases in which punctuation should be preserved, such as names like O'Reilly, so you can adjust the list of characters in the punctuation list as needed.
- Later in this chapter we will see a better approach to reusing segments of code, called Programmer Defined Functions.
- Notes:
- Code Line 8: Now we need our repetition code to loop through the string, character by character. The for loop is a good solution for this need since we can use the for in construct. The code in this example, for s in shake_string:, could be read as "for each character (s) in the string stored in the shake_string variable".
- Code Line 9: Then, inside the loop, we include a decision that checks if the character (s) in each iteration of the loop is (not) in the list of punctuation characters stored in the punctuation list we defined on Code Line 3. Notice that this if construct is very similar to the for loop construct above. The in operator is very useful with iterables, like lists. Also, notice that we do not need the else part of our decision structure because we included the not in our loop condition.
- Code Line 10: When the decision condition indicates that the character (s) in the current iteration is not punctuation, then we add that character to our new string out_string. So, as the loop iterates, each non-punctuation character gets added to the out_string
- Note:
- You can add a line of code here if you want to see each iteration of the loop to watch the out_string being built one character at a time during each iteration, like this:
for s in string_to_process: if s not in punctuation: out_string += s print(out_string) # << Add this line to see each character added per iteration print(string_to_process) print(out_string)
- You can add a line of code here if you want to see each iteration of the loop to watch the out_string being built one character at a time during each iteration, like this:
- Note:
- Code Line 11: Then, after the loop completes (based on the length of the string), we print the original string so we can compare to the out_string.
- Code Line 12: Lastly, we print the out_string to see the results of our processing.
- Notes:
- There are more efficient approaches for removing punctuation from strings, such as regular expressions, the string translate method, the filter function, and list comprehensions, all of which we will explore later.
- I would recommend changing the orginal string to something else with other punctuation included and re-running this to see the results and test the processing.
Depending on the reason we are parsing strings, in addition to dealing with punctuation, we may also need to consider whether to maintain the case of the objects in the original string or to make them all the same. In some circumstances, like the need to preserve capitalization of nouns, it is important to maintain the original case. In those circumstances, we would not need to do anything to the string after removing punctuation. However, other circumstances, like the need to be able to easily compare the ojects in the original string with other objects, it may be best to set the entire string to the same case (upper or lower).
For our purposes here, we will set the case to all lower case as we will be comparing objects from our original string with search words and it will be simpler to do so if the cases are all the same. The following code is identical to the code in the punctuation removal section above, other than the addition of the lower() method to the variable s on Code Line 10.
shake_string = "To be or not to be, that is the question."
out_string = ""
punctuation = ["!", "\"", "#", "$", "%", "&", "\'",
"(", ")", "*", "+", ",", "-", ".",
"/", ":", ";", "<", "=", ">", "?",
"@", "[", "\\", "]", "^", "_", "{",
"|", "}", "~", "`", "."]
for s in shake_string:
if s not in punctuation:
out_string += s.lower() # << This is the change to lower case the output string.
print(shake_string)
print(out_string)The decision to change case or not is often indicated in data processing requirements or becomes obvious as we develop our solutions.
Now that we have learned the fundamentals of dealing with punctuation, now we'll learn to parse strings. The primary string method we use to parse strings is the split() method. This method divides a string into tokens (substrings) based on a specified delimiter (separator) and stores the tokens in a list. By default, the delimiter is any kind of space (spaces, newlines, tabs, etc.), otherwise split() will divide the string using a separator that we specify. The result of using the split() method is a Python list containing the divided (parsed) parts (tokens) of the original string.
Here are a few examples of using split() with the default delimiter and using a specified delimiter:
Example 1
# Using split() with the default delimiter (that is, none specified)
txt = "This is a string."
lst = txt.split()
print(lst)Output
['This', 'is', 'a', 'string.']Code & Output Details
- Code Line 2: On this line I initialized a variable txt to a string.
- Code Line 3: Next, I initialize a varible to receive the result of the string's split() method.
- Code Line 4: When I print the resulting list, we can see in the output that the string has been parsed (split) based on the default delimiter of spaces, since I did not specify the delimiter.
- Notes:
- Note that each element of the resulting list contains each word in the original string.
- Also, the spaces in the original string are not part of the result, they have dropped out.
- And, note that punctuation remains in the string as part of the closest word. In this example, the ending period appears as part of the last word in the list. This is important to be aware of, depending on your application and reason for parsing, you may need to take steps to remove the punctuation.
Example 2
If we use the same code again, but this time include a specific delimiter, such as the letter s, we can see different results:
# Using split() and specifying a delimiter
txt = "This is a string."
lst = txt.split('s')
print(lst)Output
['Thi', ' i', ' a ', 'tring.']Code & Output Details
- Code Line 2: On this line I initialized a variable txt to a string.
- Code Line 3: Next, I initialize a varible to receive the result of the string's split() method, this time I included the delimiter 's'.
- Code Line 4: When I print the resulting list, we can see in the output that the string has been parsed (split) based on the letter s in the original string.
- Notes:
- The original string contained three characters s, so the resulting list contains four tokens.
- Since the split() delimiter can be any valid alphanumeric character, using 's' as our delimiter parsed the string on that character.
- Note that the 's' characters in the original string have dropped out of the tokens, this is because Python uses those characters as the delimiter which is considered not part of the output.
Example 3
Another (more common) example of using split() with a delimiter is comma-separated data where there are words or strings separated by commas, like this:
# Using split() and specifying comma as the delimiter
txt = "Bob Smith, 1234 Nowhere Lane, Someplace, UT, 84999"
lst = txt.split(',')
print(lst)Output
['Bob Smith', ' 1234 Nowhere Lane', ' Someplace', ' UT', ' 84999']Code & Output Details
- Code Line 2: On this line I initialized a variable txt to a comma-separated string containing a name, address, city, state, and zip code.
- Code Line 3: Next, I initialize a varible to receive the result of the string's split() method based on the commas as the delimiter.
- Code Line 4: When I print the resulting list, we can see in the output that the string has been parsed (split) based on the , in the original string.
- Notes:
- The original string contained four commas, so the resulting list contains five tokens.
- Since the split() delimiter is the comma, we now have a list containing each of the data elements for the name, address, city, state, and zip code.
- Note that the comma delimiters in the original string have dropped out of the tokens, this is because Python uses those characters as the delimiter which is considered not part of the output.
Once we have parsed a string, and have a list of the tokens, we can use those tokens for various purposes. Here are some examples:
Use Case: Counting Words
A common task to perform with a parsed string is to count the number of words in the string. As with most things in programming, there's more than one way to count words in a string. Since we are focued on repetition structures in this chapter, we'll look at an approach using repetition for now, and will learn more approaches as we proceed. Since the tokens of a string are stored in a list as a result of using the split() method, counting the number of words in a string is actually counting tokens in a list. Given this, we can simply iterate through the list using the for in construct and use an accumulator variable to count the number of iterations through the list.
Here's an example:
# For the sake of simplicity and focus, we will assume that punctuation
# has already been removed from the string as described above.
txt = "to be or not to be that is the question"
accumulator = 0
lst = txt.split()
for tok in lst:
accumulator += 1
print("Number of words (tokens) in the string:", accumulator)Output
Number of words (tokens) in the string: 10Code & Output Details
- Code Line 3: This line assigns our string to a variable.
- Code Line 4: We also create an accumulator variable that we use to keep a running total (accumulation) of the count of tokens in the list.
- Code Line 5: Next we'll use the split() method of the string variable to divide the string into individual words (tokens). The result of using split() is the creation of a list containing all of the tokens from the split string as individual objects.
- Code Line 6: On this line we write our repetition (loop) using the for in structure. We could read this as for each token (tok) in the list (lst)".
- Code Line 7: Inside the loop, our code block accumulates the count of the number of tokens (words) in the list that came from the string.
- Code Line 8: After the loop finishes, we print a summary statement and the number of tokens counted by the loop. This is the count of the number of words parsed from the original string.
Alternative Approach Using a Python Function
Because the split() method stores the string's tokens in a list, there is a much simpler approach of counting the number of tokens in the list without the need for looping at all, that is, using the len() function. Here's an example:
txt = "To be or not to be that is the question"
lst = txt.split()
print("Number of words:", len(lst))Note that in this alternative code, there is no need for the accumulator or the loop, in the print statement we can simply use the len() function instead. Since we are focused on repetition however, we will use repetition in the following use cases as well.
Use Case: Counting Specific Words
In this use case, we want to count the number of times a particular word (token) is in a string. The code to do this is very similar to the code we wrote in the previous example use case for counting words. The key difference is that in the code block inside of the loop, we'll need a conditional decision to determine if each word in the list matches the specified search word. When it matches, we'll increment our accumulator. When the token does not match, then we'll skip to the next token. Here's the code to accomplish this:
txt = "To be or not to be that is the question"
search_word = "be"
accumulator = 0
lst = txt.split()
for tok in lst:
if tok == search_word:
accumulator += 1
print("Number of occurrences of the word '" + search_word + "' is", accumulator, end=".")Output
Number of occurrences of the word 'be' is 2.Code & Output Details
- Code Line 1: This line assigns our string to a variable.
- Code Line 2: On this line we create another variable that will hold the word we want to count in the string, we'll call it our search_word.
- Code Line 3: We also create an accumulator variable that we use to keep a running total (accumulation) of the count of tokens that match the search_word in the list.
- Code Line 4: Next we'll use the split() method of the string variable to divide the string into individual words (tokens). The result of using split() is the creation of a list containing all of the tokens from the split string as individual objects.
- Code Line 5: On this line we write our repetition (loop) using the for in structure. We could read this as for each token (tok) in the list (lst)".
- Code Line 6: Inside the loop, our code block starts with a decision statement based on the condition of whether the token in each iteration matches the search_word.
- Code Line 7: If the token matches the search word, we increment the accumulator by 1.
- Code Line 8: After the loop finishes, we print a summary statement and the number of tokens counted by the loop. This is the count of the number of words parsed from the original string.
Use Case: Reversing a String by Word
Another use case that will add to your understanding of how to process strings that have been split() is reversing the string by word. Reversing strings usually means to reverse all of the characters, last character first to first character last. For example, if we start with the string to be or not to be and reverse it, it would turn out to be eb ot ton ro eb ot. This is reversing the order of all characters, however we want to reverse the order of the words in the string to read like be to not or be to instead. Since the split() method loads a list with the parsed tokens of the original string, there are a couple of ways in which we can reverse the word order.
Since we are focused on repetition in this chapter, we'll use a loop to reverse the order of the tokens in a list. Here's an example:
txt = "to be or not to be that is the question"
lst = txt.split()
rev_lst = []
for tok in lst:
rev_lst.insert(0, tok)
print("Original List: ", lst)
print("Reversed List: ", rev_lst)Output
Original List: ['to', 'be', 'or', 'not', 'to', 'be', 'that', 'is', 'the', 'question']
Reversed List: ['question', 'the', 'is', 'that', 'be', 'to', 'not', 'or', 'be', 'to']Code & Output Details
- Code Line 1: This line assigns our string to a variable.
- Code Line 2: Next, we use the split() string method to divide the string into tokens and store them in a list.
- Code Line 3: We'll create another variable to hold an empty list that we'll use to store the reversed list.
- Code Line 4: On this line we write our repetition (loop) using the for in structure. We could read this as for each token (tok) in the list (lst).
- Code Line 5: The code block inside the loop uses the list insert() method to insert each token at the beginning of the list, effectively reversing the order of the list.
- Code Line 6: To demonstrate the result, first we print the original list.
- Code Line 7: Then we print the reversed (copy) of the list.
Alternative Approach Using a List Method
In Python, the list data structure includes a method for reversing the list. Here's an example:
txt = "To be or not to be that is the question"
lst.reverse()
print("Reversed List:", lst)Note that in this alternative code, there is no need for a loop, we can simply use the list reverse() method. One detail to note that may be important depending on the application--the reverse() method reverses the original list's order. So, if the original order needs to be preserved, this approach of using reverse() on the original list may not be the best choice.
As introduced in Chapter 2 ↗, Data files are common resources we use to store and transmit data. There are many types of files we could engage with as programmers. For now, we will work with plain text files (files with a file extension of .txt) and comma-separate value files (files with a file extension of .csv). These two types of files are very common and learning to work with the programmatically is an important skill.
Text files (often referred to as plain text files) usually contain unstructured data. In Chapter 2 ↗ we saw that it is easy to create, read, and write the contents of a text file. In the example found there, we used the following syntax to create a file, write a word to it, and then read its contents and printed the contents:
# Writing to a text file
with open('example.txt', 'w') as file:
file.write("Hello!\n")
# Reading from a text file
with open('example.txt', 'r') as file:
content = file.read()
print(content)Writing larger amounts of text to a file is just as simple:
txt = """Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do
eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad
minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip
ex ea commodo consequat. Duis aute irure dolor in reprehenderit in
voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur
sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt
mollit anim id est laborum."""
with open('example.txt', 'w') as file:
file.write(txt)
with open('example.txt', 'r') as file:
content = file.read()
print(content)Code Details:
- Code Lines 1 thru 7: These lines assign a long string to the variable txt. Note the use of the triple-quote syntax that allows us to place the long string on multiple lines within our code. Also, the text used here is generic placeholder text from Lorem Ipsum generator ↗, which can be a very useful tool to practice processing text in Python.
- Code Lines 9 thru 14: The subsequent syntax is the same as our Chapter 2 example of reading the entire contents of a file and storing it in a variable. And we can then print the entire contents. This works well when we want to work with the entire contents of a file as a single string.